
深度学习基础:最优化算法(优化器,学习率,SGD,Adam, Momentum, NAG等)
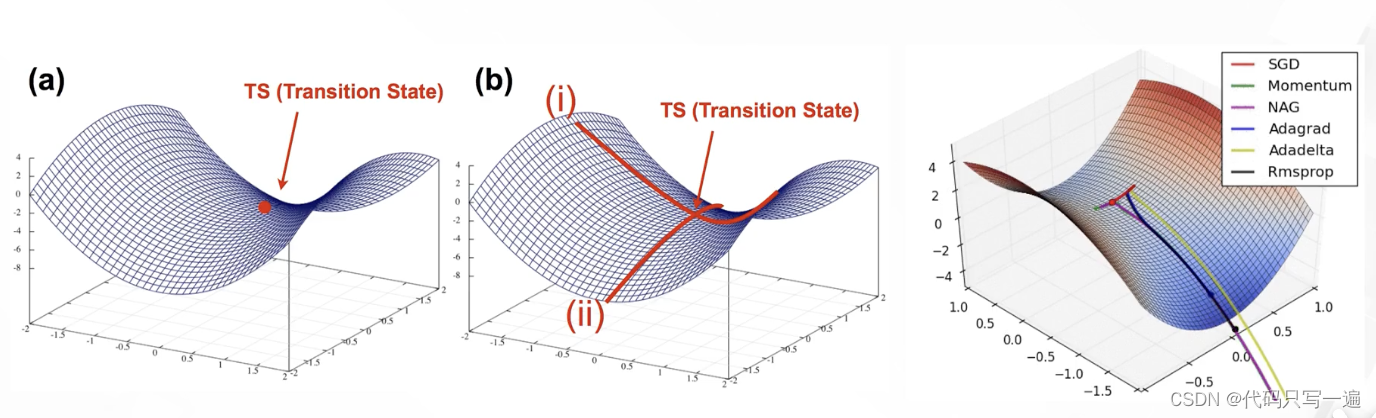
背景:机器学习用有限的训练集上的期望损失作为优化目标(i.e., 代理损失函数)。优化目标有凸函数(全局最小值)和非凸函数(很多局部极小值 不唯一 很难寻找全局最小值)。深度学习的优化就是在找不错的局部极小值。低维空间局部极小值很常见;高维空间,参数量很高,鞍点更加常见(横截面的局部极小值,某一方向上梯度下降,但另一些方向梯度上升)。
优化器的选择主要在两个方向:优化方向和学习率(优化步长)。
常见的优化算法:

更新方向的算法(SGD:沿着梯度反方向进行参数更新;优点简单,缺点不稳定,学习率敏感,迭代慢。Momentum:加速SGD,累积了之前梯度指数级衰减的移动平均。Nesterov:在标准的动量方法中添加了个校正因子,按照前一次更新梯度方向更新一步将它作为当前梯度方向。)
SGD可能会在鞍点处震荡,但使用Momentum,震荡的方向梯度相互抵消,一正一负;但在梯度小的方向逐渐累加。



更新学习率的算法:(Adagrad:自适应地为各个维度的参数分配不同的学习率,缺点后期学习率非常小。Rmsprop:不累计所有窗口,累加一定窗口的,缓解后期学习率变小。Adadelta类似,但与RMSprop不同在于学习率是动态计算的。缺点都是后期反复在局部最小值附近抖动。Adam法同时包含了动量更新与学习率调整,使用梯度的一阶矩估计和二阶矩估计来动态调整学习率,Momentum和Rmspop相结合。优点是对学习率没有那么敏感,稳定;缺点是无法收敛到好的值,泛化能力差。Adam有一系列的改进算法)
Adam 缝合SDG+Momentum和RMSProp,避免冷启动(第一步更新幅度很小)
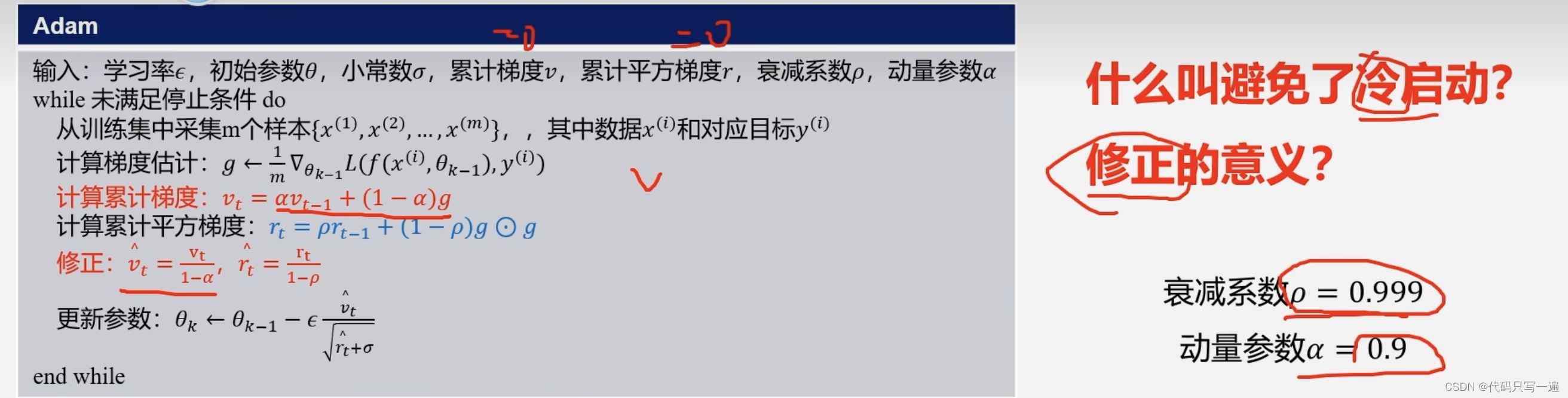




Adam使用的是梯度的一阶矩估计和二阶矩估计(梯度的二阶矩估计,也称为梯度平方的指数加权移动平均)。
真正的二阶矩的方法为何不用?其优缺点比较明显:优点是二阶的方法利用了导数的二阶信息,因为优化方向更加准确,速度更快;但是二阶需要计算或近似估计Hessian矩阵,一阶方法一次迭代更新复杂度O(N),N是参数量,二阶方法就是O(N*N),计算量大。

在实践中,Adam被推荐为使用的默认算法,并且通常比RMSProp稍微好一点。然而,作为一种替代方法,SGD+Nesterov Momentum也值得尝试。


